
In the last few months at DAKSH we have been working with a lot of big numbers. We are collecting data on all ongoing cases from 10 High Courts in India. We already have details for over five lakh case records from these High Courts, and this data grows every day. Each day sees nearly 3,000 new cases per High Court being added to our database.
One of the many aspects of our study is a detailed analysis of the data systems of each High Court. As we have discussed earlier, each High Court makes available two sets of information: cases that are to be heard every day in the form of a cause list, and the status of cases that various litigants have filed. Put together, the cause list and case status details prove to be a very important resource for building our database. A central focus of our work is to understand the life cycle of a case: the total time a case spends in the court, from the date of its institution to the date of its disposal. What we do is gather this information such that details for each case is available for a closer look. If there are, as Court News tells us, 44 lakh cases pending in the High Courts as of June 2014,[1] we should, in the span of this year, be able to collect information on all these cases.
This data has not been collated in an aggregate form for analysis in India before. I am often left wondering how to navigate the question of ‘big data’: how to analyse this much information and what it tells us about judicial processes. This is an interesting question, as different court systems around the world are now using big data analytics not only to strengthen judicial processes but also predict criminal behaviour. As a result of this, the conversation about the use of data in countries such as the US revolve around the ethics of the use of data, since the problem seems to be too much information.[2]
In India though, although much is said about the judiciary relentlessly, analyses of the judiciary are usually encumbered by a lack of sufficient data. In the Indian context, there’s no doubt that data can be used to support or refute several claims being made about the judiciary. This is DAKSH’s approach: we review various arguments or claims made about the Indian judiciary by taking a close look at what the processes in the courts are telling us through data.
It turns out however that this data that holds so much promise comes with several problems, a notable one being lack of uniformity. Some courts make more information available than others. In some courts, we have extremely detailed information against each case number that includes all orders and listings of the cases. Some High Courts have historical data – not just on what is currently in process but on cases that have already passed through the system in previous years. Some other courts however do not even specify the date of filing for cases, which means that we do not have an accurate reading on the number of days the case has been in process.
So we are able to assemble only data that is available from each High Court website, contingent upon the data management system of that court. For example, whereas we are able to parse extensive case records for the High Court of Karnataka, which manages its data efficiently, we have very limited detail for the Calcutta High Court, which does not. We detail the availability (and lack) of data on our website: http://dakshlegal.in/info/court-data/
There is no standardisation across the different court systems, despite the fact that the case information and actors in the system are the same. This is an important point to note. For a litigant, that different High Courts have different ways of organising information is not quite relevant as long as they are updated about the status of their cases. However, it seriously hinders macro-analysis since it becomes impossible to collate and aggregate information. Comparative analysis is restricted in view of the absence of comparable elements. It also points towards the other fact that while the courts are working towards more efficient data management systems, each court is a data island.
What follows below is a brief overview of the data and some of our preliminary analysis. We began collecting data in January 2015. Our records detail all cases that have been heard during the period between January and May 2015. As of May 2015, we have information for 5,86,924 cases in 10 High Courts. Of these cases, 57.2 per cent are pending across the High Courts. This is an ongoing process, and more records are added each day.
Figure 1. Cases and Pendency per High Court
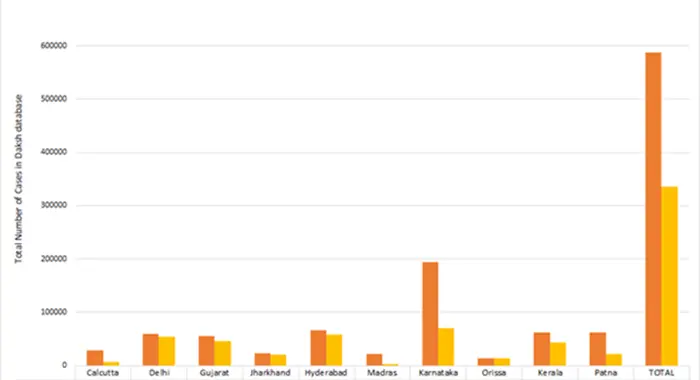
Of the total number of case records in our database, 4.3 per cent have been pending for more than 10 years. Whereas only 0.2 per cent of all cases in the High Court of Karnataka are older than 10 years, 10.6 per cent of all cases in High Court of Judicature at Hyderabad are older than 10 years.
Figure 2. Number of Cases between January and May 2015
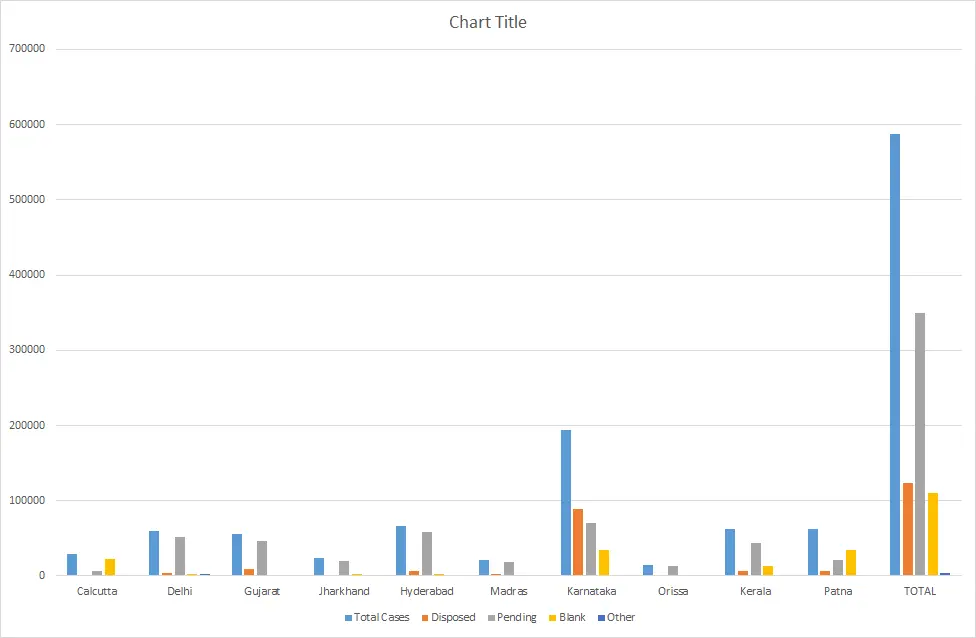
The chart above indicates the number of cases that have entered the High Courts since we started collecting data, and how they have fared in the three months they have been in the court. We find that more cases are pending than disposed of in the period between January and May 2015. In every court, there are a number of cases (indicated by the field ‘blank’) whose status (whether pending or disposed) is not known because the website does not specify their current status.
From January to May in the 10 courts, we found that whereas 6,982 cases were admitted daily in the High Court of Gujarat, only 320 cases (15 per cent) were disposed of.
Figure 3. Distribution of Civil and Criminal Cases
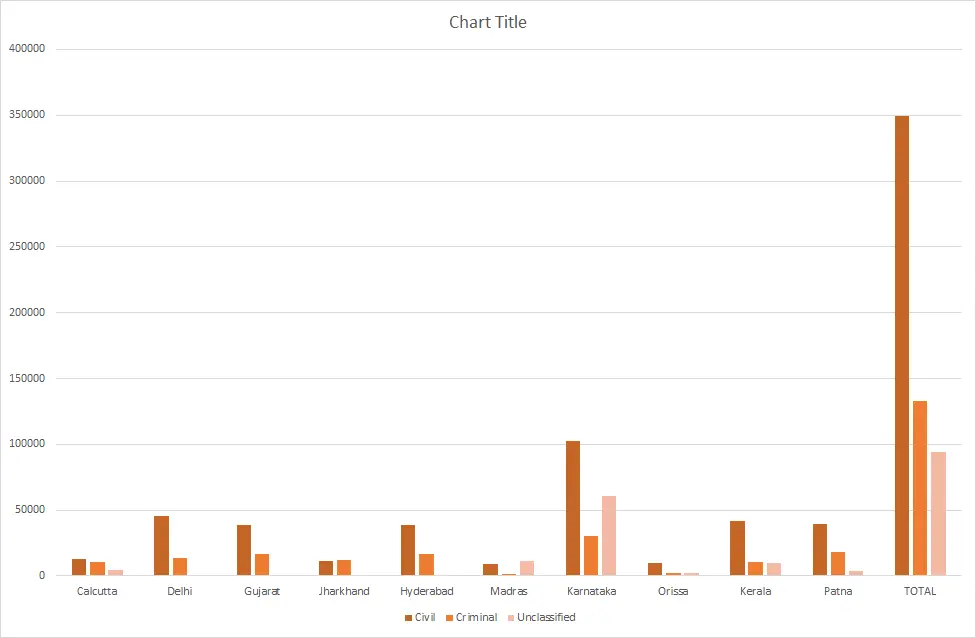
We are also interested in understanding what proportion of cases that enter each High Court are civil cases, and what proportion criminal. The chart above gives this information. Of the total number of cases in the database, nearly 60 per cent are civil and 22.9 per cent are criminal. However, 16.3 per cent of the cases in our system remain unclassified (as per the civil/criminal distinction). These are unclassified because we do not have sufficient information on case types for some courts to determine whether they are civil or criminal.[3]
We hope that this brief overview has given you a sense of the kind of information we are working with. What will follow in the coming weeks is more analysis, as well as data on six more High Courts and several district courts that DAKSH is in the process of collecting.
[1] Court News, Vol IX, April–June 2014, available online at http://supremecourtofindia.nic.in/courtnews/2014_issue_2.pdf (accessed on 05 January 2014).
[2] Jessica Pischko. 2014. ‘Punished for Being Poor: The Problem with Using Big Data in the Justice System’, PS Mag, 18 August, available online at
http://www.psmag.com/politics-and-law/punished-poor-problem-using-big-data-justice-system-88651 (accessed on 14 July 2015).
[ReviewDisclaimer]



